
How to analyze a complex text?
Storyboard 
To analyze the text, one can focus on the most frequently used nouns or some key nouns.
To do this, they are highlighted, and all the actions performed from or on them, as well as the associated characteristics, are graphed.
Similarly, one can observe the context in which these nouns appear, whether they are associated with a positive or negative environment in the given text.
ID:(4, 0)
Text segmentation
Description
Texts are typically composed of sentences that end with a period, exclamation mark, or question mark.
Each sentence or segment forms an information unit that needs to be analyzed to understand its meaning.
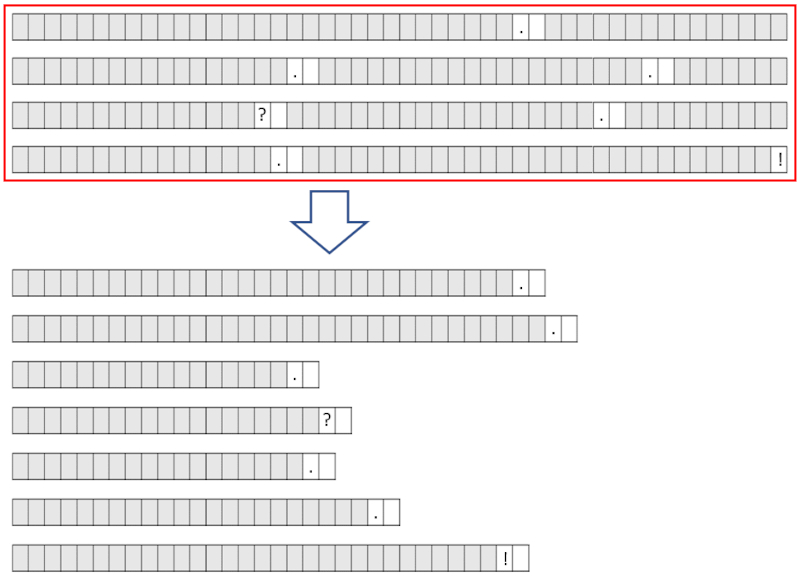
At the top, we see a paragraph composed of seven sentences. At the bottom, each sentence is listed separately to form the segments we will work with.
An example could be:
which leads to the list of segments:
The apartment of John is small.
ID:(1, 0)
Recognize tokens
Description
To analyze each segment, we must first break them down into their basic elements. Typically, these elements correspond to words, but there are situations where a word is actually a compound element with subunits. Therefore, we generalize by saying that the segment is decomposed into tokens.
An example of such compound words could be "smarter", which would have the tokens "smart" and "more".
In general, systems employ dictionaries to analyze each segment and identify the units that should be separated into individual tokens.
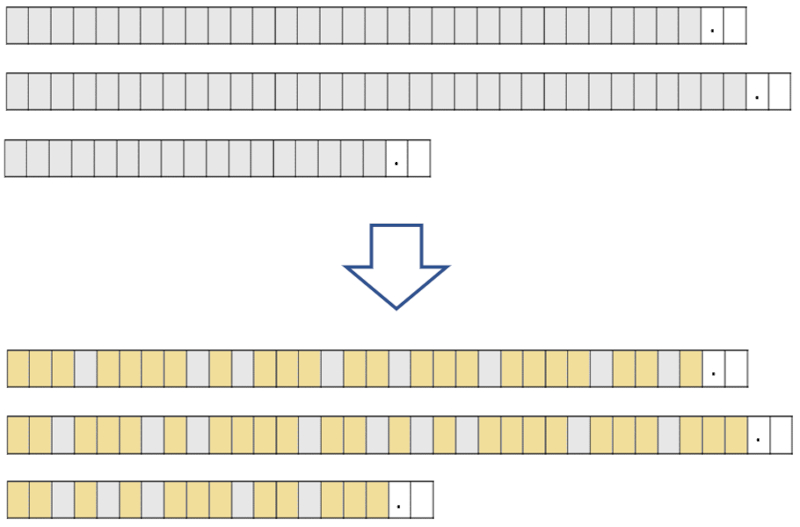
Once the segments have been identified, the next step is to determine the tokens. These can correspond to words or parts of words, especially in the case of compound words.
ID:(2, 0)
Normalization of tokens
Description
It is important to recognize when two tokens are equivalent. To achieve this, it is necessary to avoid different forms of token writing that, although they mean the same thing, are written differently. This mainly occurs in two situations:
1. Tokens can be written in uppercase or lowercase while representing the same meaning. To avoid this, all tokens are written in lowercase. This process is called text normalization.
For example:
His apartment is small.
This means modifying John, London, and His to:
his apartment is small.
2. Tokens can be written in different inflections of the word. Therefore, tokens are replaced with their base form. This process is called lemmatization of the tokens.
In the example, the word lives corresponds to the base form live, so the example becomes:
his apartment is small.
These normalization and lemmatization processes allow treating tokens uniformly, recognizing their equivalence, and avoiding redundancies or discrepancies in the way they are written.
ID:(7, 0)
Token labeling
Description
Each token plays a role within the segment based on its type.
The main types of tokens are:
| Code | Meaning |
| ADJ | adjective |
| ADP | adposition |
| ADV | adverb |
| CONJ | conjunction |
| DET | article |
| NOUN | noun |
| PROP | proper noun |
| PRON | pronoun |
| VERB | verb |
| PUNCT | punctuation |
Each token must be labeled in order to analyze the segment.
In the example, we have:
the (DET) apartment (NOUN) of (ADP) john (PROP) is (VERB) small (ADJ).
ID:(8, 0)
Recognize descriptors
Description
Adjectives can appear both associated with a noun or substantive within a segment that includes an action, or simply as a characterization without a real action taking place.
In the first case, we can exemplify it with:
where the adjective red is assigned to the noun apple, resulting in the central segment:
In the second case, we can illustrate it with the statement:
which does not involve an actual action.
Those adjectives that characterize the element described by the noun can be extracted from the sentence and left as associated descriptors. This way, the sentence is simplified to some extent without losing information. Graphically, this can be represented as nodes associated with the node of the element without being part of the flow, becoming elements, verbs, and eventually adjectives of the second type.
ID:(4, 0)
Recognize associations
Description
The simplest association is between two elements connected by verbs and/or adverbs. For example:
Here, the elements are John (PROP) and an apple (NOUN), and the action is eats (VERB).
Next, we have segments that contain multiple associations, such as:
In this case, the conjunction (CONJ) allows us to separate the segment into two:
then (ADV) goes (VERB) to (ADV) sleep (VERB).
Where the second segment can be associated with the same noun from the first one via the pronoun. Therefore, the second segment becomes:
A more complex situation arises when the order is altered, as in:
ID:(5, 0)
Referencia between segments
Description
There are often synergies between segments, as they contain additional information associated with people, institutions, and/or objects mentioned in previous segments.
In these cases, the name or noun appears multiple times in the text, which generates an association between the segments.
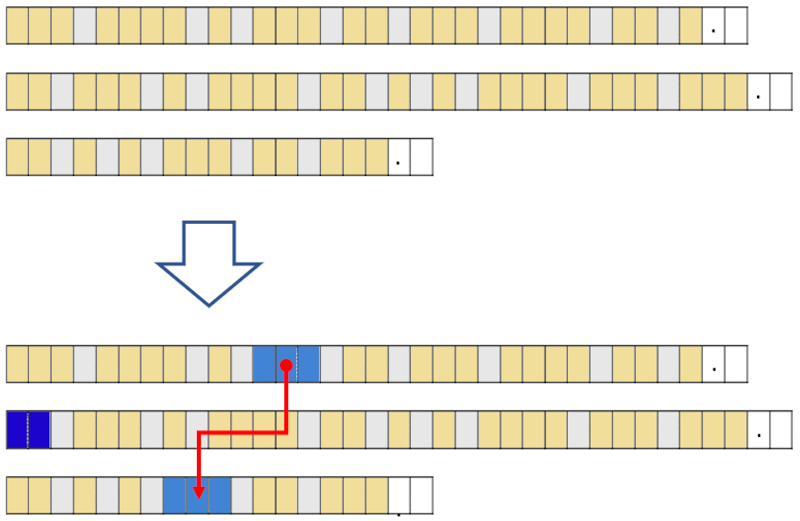
In the first and third segments, there is a common element (a noun or a substantive). This establishes a connection between the segments, allowing the descriptors to complement each other and the associations to create new relationships.
An example of such segments is:
The John's apartment is small.
which have John in common.
ID:(6, 0)
The pronoun problem
Description
The use of pronouns leads to segments making indirect references to people, organizations, or objects, making the analysis of each segment separately challenging.
Therefore, it is necessary to identify, for each pronoun in the preceding segments, the people, organizations, or objects to which they refer. This is done to establish the relationship and enable segment analysis.
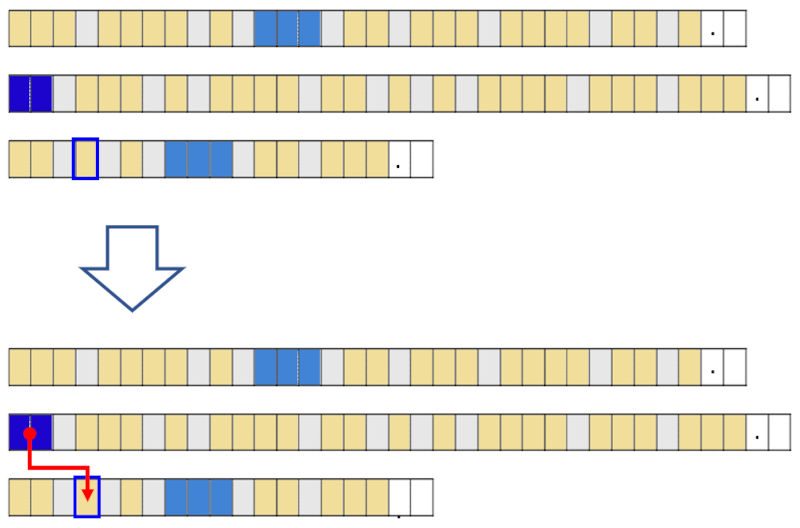
An example of such segments is:
His apartment is small.
where John should be associated with his.
Poorly constructed texts, where a name or object is inserted between the intended association and the pronoun, lead to incorrect associations.
ID:(11, 0)
Recognize pool of tokens
Description
The base segment generally consists of a noun or proper noun, a verb, and another noun or adjective. Additionally, there may be interposed adjectives that are associated with one of the nouns. A simple example would be:
The main action is eating, and the associated elements are John and the apple. The color red is just additional information about the apple.
A more complex sentence may include a subphrase, such as:
In this case, the assignment of the pronoun should associate the apple with that fell, resulting in the following subsegments:
an (DET) apple (NOUN) fell (VERB) from (ADP) the (DET) tree (NOUN)
The key to understanding the segments is to recognize the interrelated elements. These elements can be interspersed, creating recursive systems that can be misinterpreted. In some cases, the formulations themselves are so ambiguous that it is not possible to determine with certainty what the person who wrote them meant. A classic example is the famous quote by Groucho Marx:

One morning I shot an elephant in my pajamas. How he got into my pajamas, I'll never know.
The first sentence does not specify whether Groucho was in his pajamas or the elephant was... the second sentence clarifies the ambiguity.
ID:(3, 0)
Segment polarization
Description
The verbs within a segment can be associated with positive, neutral, or negative situations, thus creating the polarity of the segment.
This distinction allows for the analysis of segments to focus either on the issues (segments with negative polarity) or on the positive aspects (segments with positive polarity) of the topics being discussed.
An example of polarization is:
| Polarization | Verb |
| Negative | steal |
| Neutral | buy |
| Positive | give away |
ID:(9, 0)
Segment subjectivity
Description
A phrase or segment can have different degrees of subjectivity.
If the subjectivity is low (values close to zero), the description is based on facts or definitions that do not allow ambiguity or interpretation.
In the case of high subjectivity (values close to one), what is expressed is a personal opinion, judgment, or feeling, and it can be interpreted differently by other readers.
The value is determined based on the words included in the phrase or segment, and often it is generated through training where people associate a numerical value of subjectivity with different phrases, and the system learns to associate the phrases with that subjectivity scale.
In a first approach, subjectivity can be associated with the adjectives (ADJ) included in the sentence, as they provide characterizations of the elements represented by nouns or substantives. Often, these characterizations can be either objective observations or subjective perceptions of the person writing the text.
Examples can be:
| Subjectivity | Adjective |
| objective | red |
| subjective | beautiful |
ID:(10, 0)